
开端:机器之心Pro
AIxiv专栏是机器之心发布学术、工夫内容的栏目。往日数年,机器之心AIxiv专栏罗致报谈了2000多篇内容,掩盖全球各大高校与企业的顶级实验室,有用促进了学术调换与传播。若是您有优秀的使命想要共享,迎接投稿或者揣度报谈。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者构成的开源组织,费力于于发展大谈话模子 (LLM)、寰宇模子 (World Model)、智能体模子 (Agent Model) 的工夫以构建 AI 驱动的本质。Maitrix.org 此前收效设备了 Pandora 视频-谈话寰宇模子、LLM Reasoners,以及 MMToM-QA 评测(ACL 2024 Outstanding Paper Award)。
计划者们还是并延续构建了泛滥成灾的大范畴谈话模子(LLM),这些模子的各项智力(如推理和生成)也越来越强。因此,在万般的应用场景中对其进行性能基准测试已成为了一项要紧挑战。当今最受迎接的基准测试是 Chatbot Arena,它通过集中用户对模子输出的偏好来对 LLM 进行概述排名。但是,跟着 LLM 迟缓落地于稠密应用场景,不管是针对工业出产规画,照旧科学场景补助需求,评估 LLM 在精细化维度上的智力齐是至关热切的,举例:
数学偏激挑升分支畛域,如代数、几何、概率和微积分。不同类型的推明智力,举例标志推理、类比推理、反事实推理和社会推理。不同编程谈话的编码智力,如 Python、C++、JavaScript 和 SQL。各式科学畛域,如物理学、生物学和化学。以及任何与设备者本色应用揣度的具体问题。
如斯大范畴且精细化(以致定制化)的评估关于依赖于东谈主环球包的 Chatbot Arena 或类似的基准测试来说是一大挑战 —— 在成百上千个维度上为数千对模子(或数万对模子)集中填塞的用户投票是不切本色的。此外,由于东谈主类查询和投票进程存在噪声以及个东谈主主不雅身分,评估抑遏时时难以复现。
最近,计划者们还探索了其他的自动评估决议,通过遴荐一个(或几个)“最强” 模子(常常是 GPT-4)手脚评委来评估所有其他模子。但是,评委模子可能存在偏见,举例更倾向于遴荐与其自己作风相似的输出。基于这种评估进行模子优化可能会导致所有模子过度拟合 GPT-4 的偏见。
为了聚会这两种决议的上风,通过讹诈 “群体智能”(Chatbot Arena 依赖于东谈主群聪惠)来已矣更肃穆且更少偏见的评估,同期使该进程自动化且可膨胀到多维度智力比较,Maitrix.org 发布了 Decentralized Arena。

原文地址: https://de-arena.maitrix.orgLeaderboards: https://huggingface.co/spaces/LLM360/de-arena
图 1 展示了这些基准测试范式之间的主要区别。Decentralized Arena 的核热诚念是讹诈所有 LLM 的集体智能进行相互评估和比较。这酿成了一个去中心化、民主化的系统,在该系统中,所有被评估的 LLM 同期亦然概况评估其他模子的评审者,与依赖于中心化的 “泰斗” 模子手脚评审比拟,Decentralized Arena 概况已矣更公正的排名。
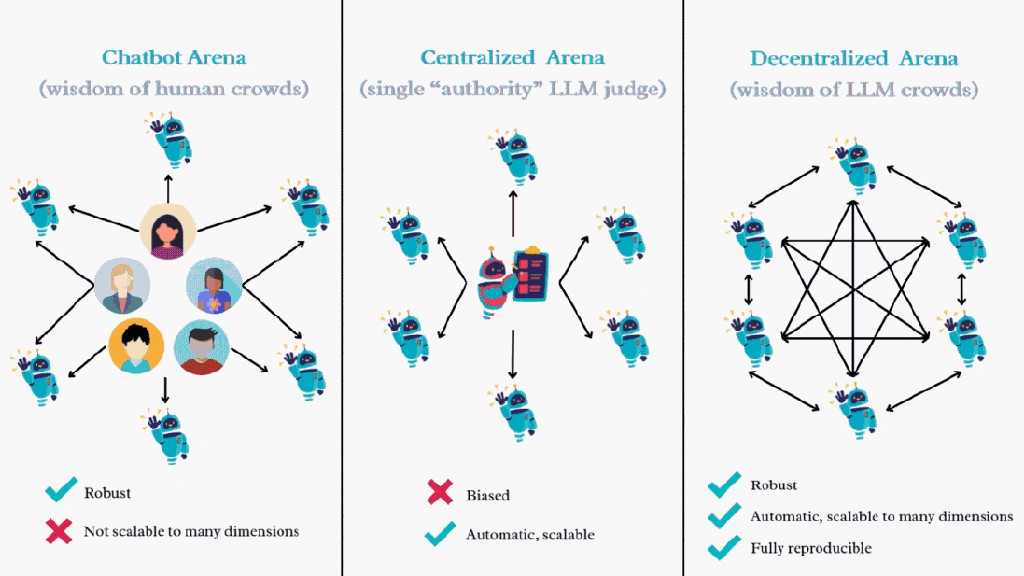
图 1:Open-ended 场景下 LLM 评估的不同范式,Decentralized Arena 聚会了两者的优点,即去中心化与自动化。

图 2:Decentralized Arena 与 Chatbot Arena 的 “全体” 排名发达出最强的揣度性。
Decentralized Arena 的重要上风包括:
肃穆且无偏:去中心化幸免了单个或少数评委模子所带来的偏见,况且破裂易通过过拟合评委模子进行操控。参与竞技场的 LLM 越多,评估越肃穆(图 4)。此外,Decentralized Arena 在 50 多个模子的 “全体” 维度上与 Chatbot Arena 达到了极端高的揣度性(95%,图 2)。自动化、易于膨胀且可定制到任何评估维度:由于用户投票的数目有限,Chatbot Arena 只可评估少数维度,而 Decentralized Arena 由于透澈自动化的假想,其概况膨胀到无穷的评估维度,况且还提供了自动遴荐特定维度问题以已矣定制化评估的决议。快速、即时的新模子排名:不异,由于自动化和高效的二分搜索排名算法,Decentralized Arena 概况即时取得新模子的评估抑遏,无需恭候数周以集中用户投票。透明且透澈可复现:所有算法、已矣和输入 / 输出齐会公开,使得抑遏透澈可复现。值得信托:凭借其肃穆性、与现存东谈主类评估抑遏的高度一致性、精细的维度分析以及透明度,Decentralized Arena 最终旨在提供一个值得社区信托的基准。
图 3 展示了最终排名榜的截图。计划团队正在连续添加更多的模子和维度,迎接来自社区的孝顺和提交!

图 3:Decentralized Arena 排名榜,包括不同维度的排名。
要领:通过大谈话模子的群体智能进行基准测试
去中心化的观念是通过让所有 LLM 充任评审,对每一双模子(即决定哪个模子的输出 “收效”,类似于 Chatbot Arena 中的东谈主类评审)进行投票。一个浅薄的作念法是让每个模子对所有其他模子对进行投票,其复杂度为 O (n^3*k),其中 n 是模子数目,k 是查询数目。当 n 和 k 齐很大时,这种要领的速率会极端慢。因此,计划团队假想了一种基于增量排名、二分搜索插入和由粗到精诊治的更高效的要领。
该计划从一小组 “种子” 模子(举例 15 个)脱手,讹诈上述浅薄要领马上对它们进行排名。然后,其他模子一个接一个地通过粗筛和精排的要领被增量插入到排名列表中。排名列表中的所有模子齐将手脚评审匡助新模子找到其位置。视频 1 讲解了这一进程。

视频流畅:https://mp.weixin.qq.com/s/4GDQYzbUna_Y1H8Ui5jHIw
视频 1: 演示大谈话模子插入进程。
要领 1: 基于二分搜索插入的粗俗排名。该要领旨在找到新模子在现时排名中的爽脆位置,其中枢念念想是使用二分搜索快速缓慢位置范围。在比较新模子与现存模子时,排名中的其他模子将手脚评审,该二分搜索的时刻复杂度为 O (k*n*logn)。要领 2: 窗口内精细排名和滑动。为了进一步细化新模子的排名,该计划将它与排名中相邻的模子进行比较(举例,排名中前后两个模子)。这些相邻的 LLM 时时是最难划分的,因此需要进行更详尽的比较。窗口外的所有其他模子将手脚评审,若是窗口内的比较导致新模子的位置发生变化,则在更新后的窗口内肖似该进程,直到排名褂讪下来。此进程类似于一个滑动窗口,引导 LLM 群体关注最具轻佻肠的 LLM 比较对,确保精准排名并最小化探讨本钱。
在上述排名进程中,该计划集中了模子的成对比较抑遏,然后使用 Bradley-Terry (BT) 要领来预想每个模子在排名中的得分。这些得分用于在模子手脚评审时赋予它们不同的权重 —— 得分较高的模子在评估其他模子对时影响更大(该计划还使用了其他浅薄的加权要领,举例基于模子排名的线性递减权重,这将在行将发布的工夫清晰中进一步商议)。这些得分在通盘排名进程中会自动诊治,最终得分在排名完成时细目。
去中心化评估系统的一个重要上风是,跟着更多模子的参与,排名将变得愈加褂讪,如图 4。

图 4: 跟着模子数目的增多,排名中的方差(暗影区域)迟缓减小,标明排名变得越来越肃穆。
通过将上述自动化评估要领应用于多个评估维度,以取得流行 LLM 的精细排名 (参见排名榜页面)。
该要领与依赖开阔东谈主工评审的 Chatbot Arena 取得了高度的揣度性(“全体” 维度的揣度性为 95%)。图 2 和图 5 展示了这些揣度性,标明 Decentralized Arena 优于其他流行的基准测试,并展示了不同维度的排名之间的关系。

图 5: 不同维度排名之间的揣度性 (底部)。
构建自界说维度:遴荐高价值问题集
Decentralized Arena 的另一个重要上风是其可膨胀性,以便于增多轻易新评估维度对 LLM 进行基准测试。用户不错随便地为我方关注的新维度创建排名。手脚演示,该计划为数学、推理、科学和编程等多个维度创建了维度排名 (排名榜)。
要为新维度确立排名,需要为该维度准备一组问题集,然后在此问题集上对 LLM 进行比较。关于某一新维度(举例数学 - 代数),需要先从各式揣度的开源数据聚拢索取并归并了一个大型运行问题集,然后进一步从中抽取一丝中枢问题以已矣高效排名。最浅薄的要领是从运行问题聚拢随即抽取问题,其抽取的问题越多,最终排名就越褂讪。
为了在较少的问题集下取得褂讪的排名(从而栽培排名效果),该计划还假想了一种新的自动问题集遴荐的要领,如图 6 所示。其中枢念念路是讹诈 LLM 的群体智能遴荐出概况在一小组 LLM 上产生一致排名的问题集,计划团队将在行将发布的工夫清晰中先容更多细节。

图 6: 新维度的自动查询遴荐。
图 7 涌现,其查询遴荐要领比随即查询抽样产生了更好且更一致的排名。

图 7: 使用其要领遴荐的问题集比随即抽样的问题集已矣了更高的揣度性和更低的方差。
更多的抑遏
该计划作念了更多的分析来以深远交融 Decentralized Arena 的抑遏。
图 8 展示了排名中 LLM 的得分偏激置信区间。

图 8: LLM 的得分和置信区间。
该计划对排名进程中每一双 LLM 的胜率和比较次数分散进行了可视化解决(“Overall” 维度)。
如图 9 和图 10 所示,LLM 的群体智能自动聚拢在难以划分的周边 LLM 对上(在图 10 中围聚对角线的模子,或在图 9 中胜率接近 50% 的模子)。比拟之下,性能差距较大的 LLM 之间的比较较为珍稀(以致被不详),从而缩短了全体探讨本钱。

图 9: 胜率分散图。

图 10: 对比次数分散图。
下一篇:亚马逊代运营是什么意念念